The following article describes a small proof of concept on how to deploy a sample JEE application. The purpose of that application is the show a transition path from traditional JEE applications requiring a huge application server installation to a more self-contained, still JEE compliant application with a smaller footprint.
You might not know that the order of static imports and ordinary imports is crucial. I stumbled upon a code snippet using a static import from a static inner class, during some codes research for a work project. Trying out that code ends up with a compiler error, saying that a standard class from the JDK was not found.
This little code snippet transforms the code formatter XML description file into a properties structure which could be applied to the JDT properties later on.
def initializeFormatter() {
def formatterDefinitions = new XmlSlurper.parse("$rootDir/misc/codeformatter.xml")
assert formatterDefinitions instanceof GPathResult
def Properties props = new Properties()
formatterDefinitions.'**'.findAll{ node ->
node.name() == 'setting'
}*.each { n ->
props.put(n.@id.text(), n.@value.text()
}
return props
}
Gradles project model provides a consistent way of expressing a version of an artifact. The following task uses the version number and makes it accessible to application code. Furthermore it adds the number of the build given by the Jenkins CI server.
/**
* Read the version number from gradle (multi-) project definition
* and add the build number from Jenkins-ci if available, otherwise use "IDE"
*/
task injectVersion << {
def lineSep = System.getProperty("line.separator", "n")
def file = file("$sourceSets.main.output.resourcesDir/version.properties")
file.newWriter().withWriter { w ->
w << "version=" << rootProject.version << lineSep
w << "buildNumber=" << (System.getenv("BUILD_NUMBER") as String ?: "IDE") << lineSep
}
}
// the inject version task requires the output folders to be already created
injectVersion.mustRunAfter processResources
// the version properties file have to be added to the classpath resource
classes.dependsOn injectVersion
It is worth to notice that the inject version task relies on the existence of the resource output directory from the „main“ source set. Therefore it is not allowed to run before the processResources has been completed and it depends on the classes task.
Someone might consider extending the processResources task putting the version.properties file creation into the doLast step like:
processResources.doLast {
def lineSep = System.getProperty("line.separator", "n")
def file = file("$sourceSets.main.output.resourcesDir/version.properties")
file.newWriter().withWriter { w ->
w << "version=" << rootProject.version << lineSep
w << "buildNumber=" << (System.getenv("BUILD_NUMBER") as String ?: "IDE") << lineSep
}
}
This works well except for changing numbers without cleaning, because gradle could not decide whether the build number has changed or is still unchanged during its configuration phase.
References
- Get the build number from Jenkins – http://blog.jensdriller.com/how-to-include-jenkins-ci-build-number-in-android-apk-name/
Kategorien
IoT starter ESP8266-12 – Basic wiring
The ESP8266(Wikipedia) chip is an affordable Ardunio compatible and WiFi enabled microprocessor. From the several modules out there this note selects the ESP8266-12 one, which features up to 12 I/O pins. Although there is a lot of information on the around the ESP8266, it was a kind of hard to figure out correct wiring for an initial setup. With the help of ESP8266 Community Wiki I ended up with the following wiring:
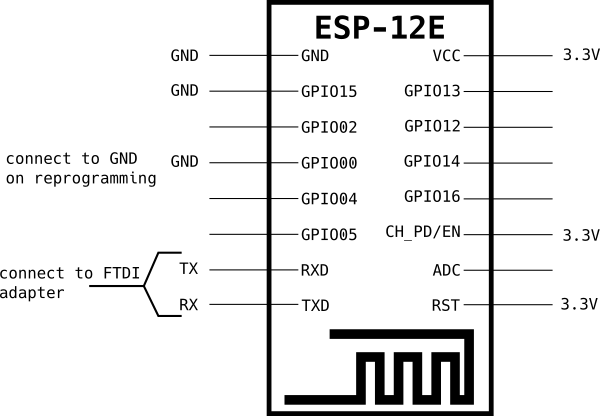
- GND –> GND (LOW)
- GPIO15 –> GND (LOW; this is required for the ESP-12 module)
- GPIO0 –> floating (disconnect; need pulled to GND (LOW) for reprogramming)
- RXD –> TX of the FTDI (serial to USB UART ) module
- TXD –> RX of the FTDI module
- VCC –> 3.3V (HIGH)
- CH_PD or EN –> 3.3V (HIGH)
- RST –> 3.3V (HIGH)
Most documentation refers to CH_PD pin, but that pin was labeled as EN on my board
For successful operation there is also a reliable 3.3V power source required. In my experience powering the ESP from the FTDI module did not work for me.
Automated provisioning of the required build environment is one of the great promises by gradle. Using gradle wrapper allows the rapid workspace setup for a new developer or on a new machine.
In organizations there are sometimes restrictions in accessing public networks and it local hosting becomes inevitable. The actual example is based on the idea hosting the gradle distribution inside the local document management system which is accessible using https only.
# gradle-wrapper.properties distributionBase=GRADLE_USER_HOME distributionPath=wrapper/dists zipStoreBase=GRADLE_USER_HOME zipStorePath=wrapper/dists distributionUrl=https://provisioning-url/gradle-2.2-bin.zip
Unfortunately the server identity is assured by a self-signed resp. signed by a local authority certificate. Running the gradle wrapper screws up yielding the following exception:
<br />> gradlew tasks
Downloading https://provisioning-url/gradle-2.2-bin.zip
Exception in thread "main" java.lang.RuntimeException: javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
at org.gradle.wrapper.ExclusiveFileAccessManager.access(ExclusiveFileAccessManager.java:78)
at org.gradle.wrapper.Install.createDist(Install.java:44)
at org.gradle.wrapper.WrapperExecutor.execute(WrapperExecutor.java:126)
at org.gradle.wrapper.GradleWrapperMain.main(GradleWrapperMain.java:58)
Caused by: javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
at sun.security.ssl.Alerts.getSSLException(Alerts.java:192)
at sun.security.ssl.SSLSocketImpl.fatal(SSLSocketImpl.java:1884)
at sun.security.ssl.Handshaker.fatalSE(Handshaker.java:276)
at sun.security.ssl.Handshaker.fatalSE(Handshaker.java:270)
at sun.security.ssl.ClientHandshaker.serverCertificate(ClientHandshaker.java:1341)
at sun.security.ssl.ClientHandshaker.processMessage(ClientHandshaker.java:153)
at sun.security.ssl.Handshaker.processLoop(Handshaker.java:868)
at sun.security.ssl.Handshaker.process_record(Handshaker.java:804)
at sun.security.ssl.SSLSocketImpl.readRecord(SSLSocketImpl.java:1016)
at sun.security.ssl.SSLSocketImpl.performInitialHandshake(SSLSocketImpl.java:1312)
at sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:1339)
at sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:1323)
at sun.net.www.protocol.https.HttpsClient.afterConnect(HttpsClient.java:563)
at sun.net.www.protocol.https.AbstractDelegateHttpsURLConnection.connect(AbstractDelegateHttpsURLConnection.java
:185)
at sun.net.www.protocol.http.HttpURLConnection.getInputStream(HttpURLConnection.java:1300)
at sun.net.www.protocol.https.HttpsURLConnectionImpl.getInputStream(HttpsURLConnectionImpl.java:254)
at org.gradle.wrapper.Download.downloadInternal(Download.java:56)
at org.gradle.wrapper.Download.download(Download.java:42)
at org.gradle.wrapper.Install$1.call(Install.java:57)
at org.gradle.wrapper.Install$1.call(Install.java:44)
at org.gradle.wrapper.ExclusiveFileAccessManager.access(ExclusiveFileAccessManager.java:65)
... 3 more
Caused by: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
at sun.security.validator.PKIXValidator.doBuild(PKIXValidator.java:385)
at sun.security.validator.PKIXValidator.engineValidate(PKIXValidator.java:292)
at sun.security.validator.Validator.validate(Validator.java:260)
at sun.security.ssl.X509TrustManagerImpl.validate(X509TrustManagerImpl.java:326)
at sun.security.ssl.X509TrustManagerImpl.checkTrusted(X509TrustManagerImpl.java:231)
at sun.security.ssl.X509TrustManagerImpl.checkServerTrusted(X509TrustManagerImpl.java:126)
at sun.security.ssl.ClientHandshaker.serverCertificate(ClientHandshaker.java:1323)
... 19 more
Caused by: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
at sun.security.provider.certpath.SunCertPathBuilder.engineBuild(SunCertPathBuilder.java:196)
at java.security.cert.CertPathBuilder.build(CertPathBuilder.java:268)
at sun.security.validator.PKIXValidator.doBuild(PKIXValidator.java:380)
... 25 more
The problem is that the HTTPS connection could not be validated because there is no trusted certificate for the provisioning url available.
The solution is to enhance the truststore with the certificate or the authority used in the provisioning url:
#create or copy an existing truststore eq. form jdk > cp $JAVA_HOME/jre/lib/security/cacerts certs.jks # import your certifiact into certs.jks > keytool -importcert -file self-signed.pem -keystore certs.jks
and tell gradlew to use this truststore instead of the original one. Gradles behavior can be adjusted by modifying the gradle.properties file in the root directory of your gradle project (for more information see „The Build Environment“ from the user guide).
# gradle.properties systemProp.javax.net.ssl.trustStore=certs.jks # could set password as well # javax.net.ssl.trustStorePassword=changeit
Calling gradlew again should kick off downloading the gradle distribution and running your tasks like a charm.
Update 27/10/2016
Changed password property to match the truststore. Thanks to Thomas for his advice.
Rust-taglib provides Rust bindings to the TagLib library. TagLib is a library for reading and editing meta data information of various audio formats. Recently the Rust wrapper supports the operations exposed by the simple C binding interface only.
Visiting the Goto Conference in Berlin let me code a quick hack of a personal conference planner GotoCo . GotoCo is a small mobile application based on web technologies using the Ionic framework. It features to access the conference information, store them locally for later use and build your personal conference schedule. Visit http://apps.mindcrime-ilab.de/gotoco/index.html to check out the app – but due to the conference is already over it might not that useful anymore.
Conference sessions and tracks become more or less fixed after some point and network usage is always critical on mobile devices (limited speed or transfer volume). Applying a cache mechanims seems appropriate in order to make the app more responsive and mobile friendly.

„Mastering AngularJS Directives“ by Josh Kurz is a deep dive into the magic of writing directives using the AngularJS framework by Google. This review is based on the eBook which was amply sponsored by Packt Publishing. The book is divided into nine chapters on roughly 200 pages.
Sometimes it is useful to set up a SoapUI test for simulating different usage scenarios randomly. The following solution provides a random selection from prepared test steps resulting in a different behavior of the tested service.